Go内存管理
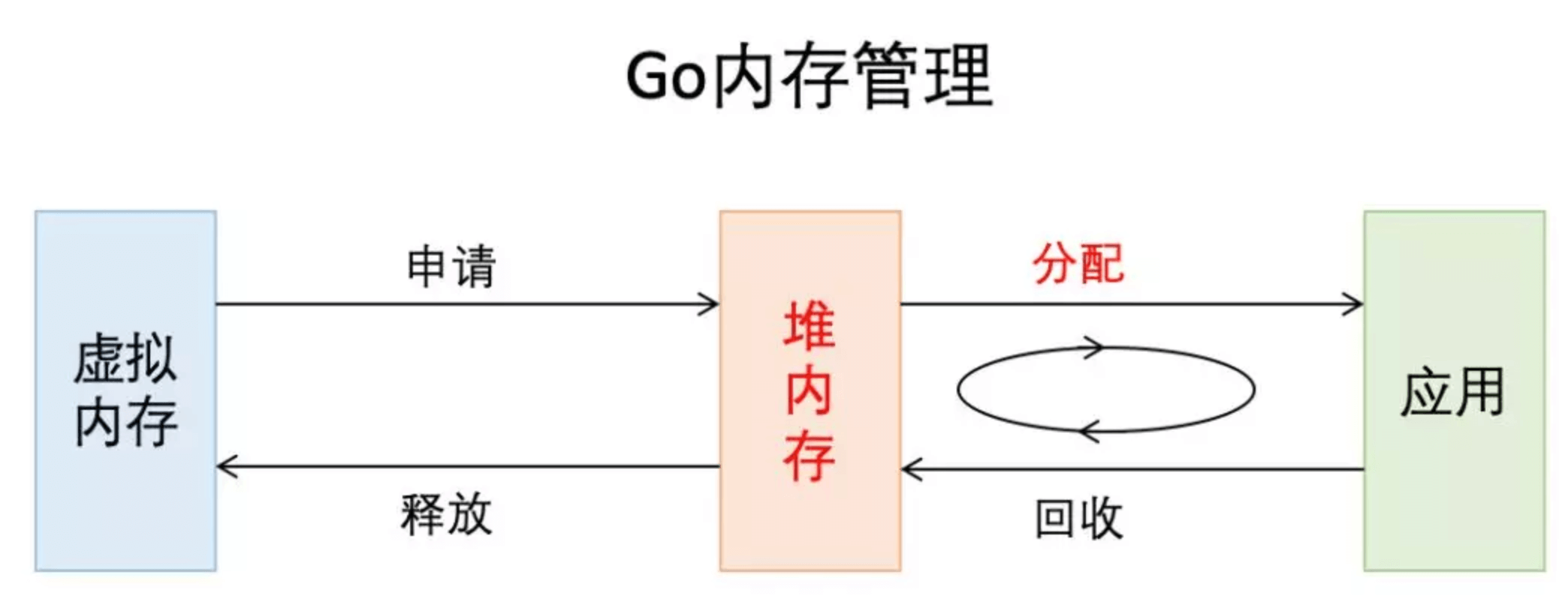
Go内存管理基于TCMalloc,使用连续虚拟地址,以页(8k)为单位、多级缓存进行管理;在分配内存时,需要对size进行对齐处理,根据best-fit找到合适的mspan,对未用完的内存还会拆分成其他大小的mspan继续使用。
在new一个object时(忽略逃逸分析),根据object的size做不同的分配策略:
- 极小对象(size<16byte)直接在当前P的mcache上的tiny缓存上分配;
- 小对象(16byte <= size <= 32k)在当前P的mcache上对应slot的空闲列表中分配,无空闲列表则会继续向mcentral申请(还是没有则向mheap申请);
- 大对象(size>32k)直接通过mheap申请。
1. 内存分配知识
- 计算机系统的主存被组织成一个由M个连续的字节大小的单元组成的数组,每个字节都有一个唯一的物理地址(PA)
- 现代处理器使用的是一种为虚拟寻址(VA)的寻址形式,最少的寻址单位是字
- 虚拟地址映射物理地址是通过读取页表(page table)进行地址翻译完成的:页表存放在物理存储器中
- MMU(内核吧物理页作为内存管理的基本单位)以页(page)大小为单位来管理系统中的页表
- 在虚拟存储器的习惯说法中,DRAM缓存不命中的成为:缺页
- page的结构与物理页相关,而非与虚拟页相关
- 系统中的每个物理页都要分配一个page结构体
在了解Go的内存分配器原理之前,我们先了解一下“动态存储分配器”。
2. 动态存储分配器
动态存储分配器维护着一个进程的虚拟存储区域,这个区域称为 “堆”,堆可以视为一组大小不同的 “块”(chunk: 连续的虚拟存储片,无论内存分配器和垃圾回收算法都依赖连续地址)的集合,并交由动态存储器维护。
动态分配器主要分为:
- 显式:常见的malloc.
- 隐式:垃圾回收.
在Go中,分配器将其管理(大块 –> 小块)的内存块分为两种:
- span:由多个连续的页(page)组成的大块内存.
- object:将span按特定大小切分多个小块,每个小块可存储一个对象.
按照其用途,span面向内部管理,object面向对象分配.
分配器按页数来区分不同大小的span。比如,以页数为单位将span存放到管理数组中,需要时就以页数为索引进行查找。当然,span大小并非固定不变。在获取闲置span时,如果没找到大小合适的,那就返回页数更多的,此时会引发裁剪操作,多余部分将构成新的span被放回管理数组。分配器还会尝试将地址相邻的空闲span合并,以构建更大的内存块,减少碎片,提供更灵活的分配策略。
我们在go的malloc.go代码中:
const (
_PageShift = 13
_PageSize = 1 << _PageShift
_PageMask = _PageSize - 1
)可以看到,用于存储对象的object,按照8字节倍数分为n种。这种方式虽然会造成一些内存浪费,但分配器只须面对有限的几种规格的小块内存,优化了分配和复用管理策略。
分配器会尝试将多个微小对象组合到一个object快内,以节约内存。我们看到msize.go的部分:
var class_to_size [_NumSizeClasses]int32
var class_to_allocnpages [_NumSizeClasses]int32
var class_to_divmagic [_NumSizeClasses]divMagic
var size_to_class8 [1024/8 + 1]int8
var size_to_class128 [(_MaxSmallSize-1024)/128 + 1]int8
func sizeToClass(size int32) int32 {
if size > _MaxSmallSize {
throw("invalid size")
}
if size > 1024-8 {
return int32(size_to_class128[(size-1024+127)>>7])
}
return int32(size_to_class8[(size+7)>>3])
}分配器初始化时,会构建对照表存储大小和规格对应关系,包括用来切分的span页数。
// Tunable constants.
_MaxSmallSize = 32 << 10从上面的代码段,我们大概可以指定若对象大小超出特定阈值限制,会被当做大对象特别对待。
3. mmap函数
Unix进程可以使用mmap函数来创建新的虚拟存储区域并将对象映射到这些区域中。
mmap函数要求内核创建一个新的虚拟存储区域,最好是从起始地址start开始的一个区域,并将文件描述符fd指定的对象的一个连续的片(chunk)映射到新的区域。
4. 数据频繁分配与回收
对于有效地进行数据频繁分配与回收,减少碎片,一般有两种手段:
- 空闲链表: 提供直接可供使用,已分配的结构块,缺点是不能全局控制.
- slab:linux提供的,可以把不同的对象划分为所谓高速缓存组.
5. Go的内存分配
Go的内存分配器是采用google自家的tcmalloc,tcmalloc是一个带内存池的分配器,底层直接调用mmap函数,并使用bestfit进行动态分配。
Go为每个系统线程分配了一个本地MCache,少量的地址分配就是从MCache分配的,并且定期进行垃圾回收,所以可见go的分配器包含了显式与隐式的调用。
Go定义的小块内存,大小上是指32K或以下的对象,go底层会把这些小块内存按照指定规格(大约100种)进行切割,为了避免随意切割,申请任意字节内存时会向上取整到接近的块,将整块分配(从空闲链表)给到申请者。
Go内存分配主要组件:
MCache:层次与MHeap类似,对于每个尺寸的类别都有一个空闲链表。每个M都有自己的局部Mcache(小对象从它取,无需加锁),这就是Go能够在多线程中高效内存管理的重要原因.
MCentral:在无空闲内存的时候,向Mheap申请一个span,而不是多个,申请的span包含多少个page由central的sizeclass来确定(跨进程复用)
MHeap:负责将MSpan组织和管理起来。
(1). 分配过程:从free中分配,如果发生切割则将剩余的部分放回到free中.
(2). 回收过程:回收一个Mspan时,首选查找它相邻的地址,再通过map映射得到对应的Mspan,如果Mspan的state是未使用,则可以将 两者进行合并。最后将这页或者合并后的页归还到free分配池或者large中。
6. Go的内存模型
Go的内存模型可以视为两级的内存模型:
第一级:Mheap为主要组件:分配的单位是页,但管理的单位是MSpan,每次分配都是用bestFit的原则分配连续的页,回收是采用位图的方式。
第二级:MCache为主要组件:相当于一个内存池, 回收采用引用计数器.
分配场景:
为对象分配内存须区分是在栈上分配还是在堆上分配。通常情况下,编译器有责任尽可能使用寄存器和栈来存储对象,这有助于提升性能,减少垃圾回收器的压力。
应用示例:
package main
func patent() *int {
x := new(int)
*x = 1234
return x
}
func main() {
println(*patent())
}我们禁止内联优化来编译上面的代码:
> go build -gcflags="-l" -o patent main.go得到的结果是:
main.go:3 0x2040 65488b0c25a0080000 GS MOVQ GS:0x8a0, CX
main.go:3 0x2049 483b6110 CMPQ 0x10(CX), SP
main.go:3 0x204d 7639 JBE 0x2088
main.go:3 0x204f 4883ec18 SUBQ $0x18, SP
main.go:3 0x2053 48896c2410 MOVQ BP, 0x10(SP)
main.go:3 0x2058 488d6c2410 LEAQ 0x10(SP), BP
main.go:4 0x205d 488d05dc3b0500 LEAQ 0x53bdc(IP), AX
main.go:4 0x2064 48890424 MOVQ AX, 0(SP)
main.go:4 0x2068 e823a70000 CALL runtime.newobject(SB)
main.go:4 0x206d 488b442408 MOVQ 0x8(SP), AX
main.go:5 0x2072 48c700d2040000 MOVQ $0x4d2, 0(AX)
main.go:6 0x2079 4889442420 MOVQ AX, 0x20(SP)
main.go:6 0x207e 488b6c2410 MOVQ 0x10(SP), BP
main.go:6 0x2083 4883c418 ADDQ $0x18, SP
main.go:6 0x2087 c3 RET
main.go:3 0x2088 e893720400 CALL runtime.morestack_noctxt(SB)
main.go:3 0x208d ebb1 JMP main.patent(SB)
:-1 0x208f cc INT $0x3从结果的 CALL runtime.newobject(SB) ,证明我们的对象在堆上进行分配了。
但当使用默认参数,我们观察下结果:
> go build -o patent main.go当我们跟上面一样分析test的分配情况时:
> go tool objdump -s "main\.patent" patent命令执行后,并没有输出, 我们分析下main方法:
> go tool objdump -s "main\.main" patent得到的结果如下:
main.go:9 0x2040 65488b0c25a0080000 GS MOVQ GS:0x8a0, CX
main.go:9 0x2049 483b6110 CMPQ 0x10(CX), SP
main.go:9 0x204d 763d JBE 0x208c
main.go:9 0x204f 4883ec18 SUBQ $0x18, SP
main.go:9 0x2053 48896c2410 MOVQ BP, 0x10(SP)
main.go:9 0x2058 488d6c2410 LEAQ 0x10(SP), BP
main.go:10 0x205d 48c7442408d2040000 MOVQ $0x4d2, 0x8(SP)
main.go:10 0x2066 e875210200 CALL runtime.printlock(SB)
main.go:10 0x206b 48c70424d2040000 MOVQ $0x4d2, 0(SP)
main.go:10 0x2073 e8b8280200 CALL runtime.printint(SB)
main.go:10 0x2078 e8e3230200 CALL runtime.printnl(SB)
main.go:10 0x207d e8ee210200 CALL runtime.printunlock(SB)
main.go:11 0x2082 488b6c2410 MOVQ 0x10(SP), BP
main.go:11 0x2087 4883c418 ADDQ $0x18, SP
main.go:11 0x208b c3 RET
main.go:9 0x208c e83f720400 CALL runtime.morestack_noctxt(SB)
main.go:9 0x2091 ebad JMP main.main(SB)这表明内联优化后的代码没有调用newobject在堆上分配内存。
编译器这么做的目的是:没有内联时,需要在两个栈帧间传递对象,因此在堆上分配而不是返回一个失效栈帧的数据。而当内联后,实际上就成看main栈帧内的局部变量,无需到堆上操作。
内存分配流程:
1、将小对象的大小向上取整到一个对应的尺寸类别(大约100种),查找相应的MCache的空闲链表,如果链表不空,直接从上面分配一个对象,这个过程不加锁
2、如果MCache自由链表是空的,通过MCentral的自由链表取一些对象进行补充
3、如果MCentral的自由链表是空的,则往MHeap中取用一些页对MCentral进行补充,然后将这些内存截断成特定规格
4、如果MHeap空或者没有足够大的页的情况下,从操作系统分配一组新的页面,一般在1MB以上
Go分配流程核心源码实现:
func mallocgc(size uintptr, typ *_type, flags uint32) unsafe.Pointer {
if gcphase == _GCmarktermination {
throw("mallocgc called with gcphase == _GCmarktermination")
}
if size == 0 {
return unsafe.Pointer(&zerobase)
}
if flags&flagNoScan == 0 && typ == nil {
throw("malloc missing type")
}
if debug.sbrk != 0 {
align := uintptr(16)
if typ != nil {
align = uintptr(typ.align)
}
return persistentalloc(size, align, &memstats.other_sys)
}
// assistG is the G to charge for this allocation, or nil if
// GC is not currently active.
var assistG *g
if gcBlackenEnabled != 0 {
// Charge the current user G for this allocation.
assistG = getg()
if assistG.m.curg != nil {
assistG = assistG.m.curg
}
// Charge the allocation against the G. We'll account
// for internal fragmentation at the end of mallocgc.
assistG.gcAssistBytes -= int64(size)
if assistG.gcAssistBytes < 0 {
// This G is in debt. Assist the GC to correct
// this before allocating. This must happen
// before disabling preemption.
gcAssistAlloc(assistG)
}
}
// Set mp.mallocing to keep from being preempted by GC.
mp := acquirem()
if mp.mallocing != 0 {
throw("malloc deadlock")
}
if mp.gsignal == getg() {
throw("malloc during signal")
}
mp.mallocing = 1
shouldhelpgc := false
dataSize := size
c := gomcache()
var s *mspan
var x unsafe.Pointer
if size <= maxSmallSize {
if flags&flagNoScan != 0 && size < maxTinySize {
//小对象分配
off := c.tinyoffset
// Align tiny pointer for required (conservative) alignment.
if size&7 == 0 {
off = round(off, 8)
} else if size&3 == 0 {
off = round(off, 4)
} else if size&1 == 0 {
off = round(off, 2)
}
if off+size <= maxTinySize && c.tiny != 0 {
// The object fits into existing tiny block.
x = unsafe.Pointer(c.tiny + off)
c.tinyoffset = off + size
c.local_tinyallocs++
mp.mallocing = 0
releasem(mp)
return x
}
// Allocate a new maxTinySize block.
s = c.alloc[tinySizeClass]
v := s.freelist
if v.ptr() == nil {
systemstack(func() {
c.refill(tinySizeClass)
})
shouldhelpgc = true
s = c.alloc[tinySizeClass]
v = s.freelist
}
s.freelist = v.ptr().next
s.ref++
// prefetchnta offers best performance, see change list message.
prefetchnta(uintptr(v.ptr().next))
x = unsafe.Pointer(v)
(*[2]uint64)(x)[0] = 0
(*[2]uint64)(x)[1] = 0
// See if we need to replace the existing tiny block with the new one
// based on amount of remaining free space.
if size < c.tinyoffset || c.tiny == 0 {
c.tiny = uintptr(x)
c.tinyoffset = size
}
size = maxTinySize
} else {
var sizeclass int8
if size <= 1024-8 {
sizeclass = size_to_class8[(size+7)>>3]
} else {
sizeclass = size_to_class128[(size-1024+127)>>7]
}
size = uintptr(class_to_size[sizeclass])
s = c.alloc[sizeclass]
v := s.freelist
if v.ptr() == nil {
systemstack(func() {
c.refill(int32(sizeclass))
})
shouldhelpgc = true
s = c.alloc[sizeclass]
v = s.freelist
}
s.freelist = v.ptr().next
s.ref++
// prefetchnta offers best performance, see change list message.
prefetchnta(uintptr(v.ptr().next))
x = unsafe.Pointer(v)
if flags&flagNoZero == 0 {
v.ptr().next = 0
if size > 2*sys.PtrSize && ((*[2]uintptr)(x))[1] != 0 {
memclr(unsafe.Pointer(v), size)
}
}
}
} else {
var s *mspan
shouldhelpgc = true
systemstack(func() {
s = largeAlloc(size, flags)
})
x = unsafe.Pointer(uintptr(s.start << pageShift))
size = s.elemsize
}
if flags&flagNoScan != 0 {
// All objects are pre-marked as noscan. Nothing to do.
} else {
if typ == deferType {
dataSize = unsafe.Sizeof(_defer{})
}
heapBitsSetType(uintptr(x), size, dataSize, typ)
if dataSize > typ.size {
// Array allocation. If there are any
// pointers, GC has to scan to the last
// element.
if typ.ptrdata != 0 {
c.local_scan += dataSize - typ.size + typ.ptrdata
}
} else {
c.local_scan += typ.ptrdata
}
publicationBarrier()
}
if gcphase == _GCmarktermination || gcBlackenPromptly {
systemstack(func() {
gcmarknewobject_m(uintptr(x), size)
})
}
if raceenabled {
racemalloc(x, size)
}
if msanenabled {
msanmalloc(x, size)
}
mp.mallocing = 0
releasem(mp)
if debug.allocfreetrace != 0 {
tracealloc(x, size, typ)
}
if rate := MemProfileRate; rate > 0 {
if size < uintptr(rate) && int32(size) < c.next_sample {
c.next_sample -= int32(size)
} else {
mp := acquirem()
profilealloc(mp, x, size)
releasem(mp)
}
}
if assistG != nil {
// Account for internal fragmentation in the assist
// debt now that we know it.
assistG.gcAssistBytes -= int64(size - dataSize)
}
if shouldhelpgc && gcShouldStart(false) {
gcStart(gcBackgroundMode, false)
}
return x
}Go也有happens-before ,go happens-before常用的三原则是:
- 对于不带缓冲区的channel,对其写happens-before对其读.
- 对于带缓冲区的channel,对其读happens-before对其写.
- 对于不带缓冲的channel的接收操作 happens-before 相应channel的发送操作完成.
